2025. 3. 8. 15:17ㆍDA 서적 정리
목차
1. JSON, XML 문서 살펴보기
2. API 사용해서 데이터 가져오기
3. 웹스크래이핑 해서 데이터 가져오기
4. 데이터 정제 메서드 정리
5. 정규표현식으로 문자열 다루기
6. 기술 통계 메서드 정리
7. 시각화
1. JSON, XML 문서 살펴보기
JSON 문서
import json
# JSON 객체는 파이썬의 딕셔너리와 비슷하다
# API로 받은 데이터가 JSON 문자열일 때
# 다음과 같은 방법을 파이썬에서 사용할 수 있게 해준다
# 파이썬 딕셔너리 객체 생성
d = {'name' : '혼공 데이터분석', 'year' : 2022}
print(d)
print(type(d))
# 파이썬 딕셔너리 -> JSON 문자열로 변환
d_str = json.dumps(d, ensure_ascii= False) # 한글을 포함한 파일은 이 옵션을 사용한다
print(d_str)
print(type(d_str))
# JSON 문자열 -> 파이썬 딕셔너리로 변환
d2 = json.loads(d_str)
print(d2)
print(type(d2))
print('\n') # 줄바꿈
# JSON 문자열 -> 파이썬 데이터 프레임으로 변환
d_str = json.dumps([d], ensure_ascii= False)
df = pd.read_json(d_str)
print(df)
print(type(df))
# d를 대괄호로 감싸주는 이유는 read_json은 단일 딕셔너리가 아니라 여러개의 딕셔너리를 받아야하기 때문이다
XML 데이터 다루기
# XML 사용 라이브러리
import xml.etree.ElementTree as et
x_str = """
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
"""
# XML 문자열 -> 파이썬 객체 변환
book = et.fromstring(x_str)
# 부모 태그 확인
print('부모 태그', book.tag)
# 자식 태그 확인
book_childs = list(book)
print('자식 태그', book_childs)
# 자식 태그의 값 불러오기 (findtext 메서드)
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print('\n 자식 태그 세부 확인')
print(name)
print(author)
print(year)
조금 더 복잡한 XML 문서 다루기
# 부모 엘리먼트 books 안에 엘리먼트 book 안의 엘리먼트 name,author,year 안의 값
# 으로 이루어진 XML 문서
x2_str = """
<books>
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
<book>
<name>혼자 공부하는 머신러닝+딥러닝</name>
<author>박해선</author>
<year>2020</year>
</book>
</books>
"""
# 부모 엘리먼트 반환 (et.fromstring는 가장 상위 부모 엘리먼트만 반환한다)
books = et.fromstring(x2_str)
print('부모 엘리먼트', books.tag)
print()
# 최상위 엘리먼트인 books안의 모든 book 엘리먼트에 접근해서 book의 하위 엘리먼트의 값들을 출력
for book in books.findall('book'): # 모든 book 엘리먼트들을 선택하기위해 findall 메서드를 사용!
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
print()
2. API 사용하기
API는 프로그램끼리 소통할 수 있는 매개체이며
API를 사용해서 사이트에서 공개한 데이터 베이스에 접근해서 데이터를 가져올 수 있다
API는 주로 CSV, JSON, XML 형식으로 데이터를 전달하며
그 중 JSON, XML이 다양한 데이터의 구조를 잘 반영한다
이 교재에서는 다음의 순서를 거쳐서 '도서관 정보나루' 사이트의
API를 활용해서 실습한다 목표는 '인기 대출 도서 조회' 이다
순서
1. API를 사용할 사이트 접속
2. 로그인
3. 해당 사이트의 API 활용방법이 적힌 메뉴얼을 찾는다
4. API 사용자격과 같은 역할을하는 인증키를 요청한다
5. 메뉴얼에 적힌 HTTP GET 방식을 통해 데이터 호출 URL을 작성
6. 호출된 데이터를 파이썬에서 reauests 패키지를 이용해 가져온다
7. API를 사용해서 데이터 가져오기 끝


# API 호출하는 패키지 reauests
import requests
# API 호출 링크 (''' ''' 따옴표 세개로 감싸서 줄을 바꿔가면서 쓰면 오류가 생긴다 그래서 그냥 한줄로 썼다)
url = 'http://data4library.kr/api/loanItemSrch?format=json&startDt=2021-04-01&endDt=2021-04-30&age=20&authKey=978bc2bfa7d6871540e74e283764f535695ad7dd7c35830026ff756fa2c7d9e1'
# 위 링크 해석
# http://data4library.kr/api/loanItemSrch # 호출 주소
# ?format=json # 불러올 데이터 형식을 JSON으로 설정
# &startDt=2021-04-01 # 대출 데이터 조회 시작 날짜
# &endDt=2021-04-30 # 대출 데이터 조회 종료 날짜
# &age=20 # 조회할 연령대 (20대)
# &authKey=978bc2bfa7d6871540e74e283764f535695ad7dd7c35830026ff756fa2c7d9e1 # 인증키
# URL을 requests 패키지로 불러오기
r = requests.get(url)
# 파이썬 객체로 변경
# (json()는 respones 객체 -> 파이썬 객체로 변환
# json.loads() 문자열 -> 파이썬 객체로 변환)
data = r.json()
# 가져온 데이터 확인
data
# data 딕셔너리는 respones라는 하나의 상위 키가 존재한다
# 이 키의 값은 딕셔너리이다
# 이 딕셔너리의 키 중에 'docs'라는 키의 값은 리스트이며
# 이 리스트 안에는 여러가지 딕셔너리가 있다
# 이 딕셔너리들 안의 doc라는 키의 값들을 모두 출력
# response 안쪽의 docs 안쪽의 doc의 값들
books = []
for d in data['response']['docs']:
books.append(d['doc'])
# doc는 인기도서들의 정보를 담고있다
books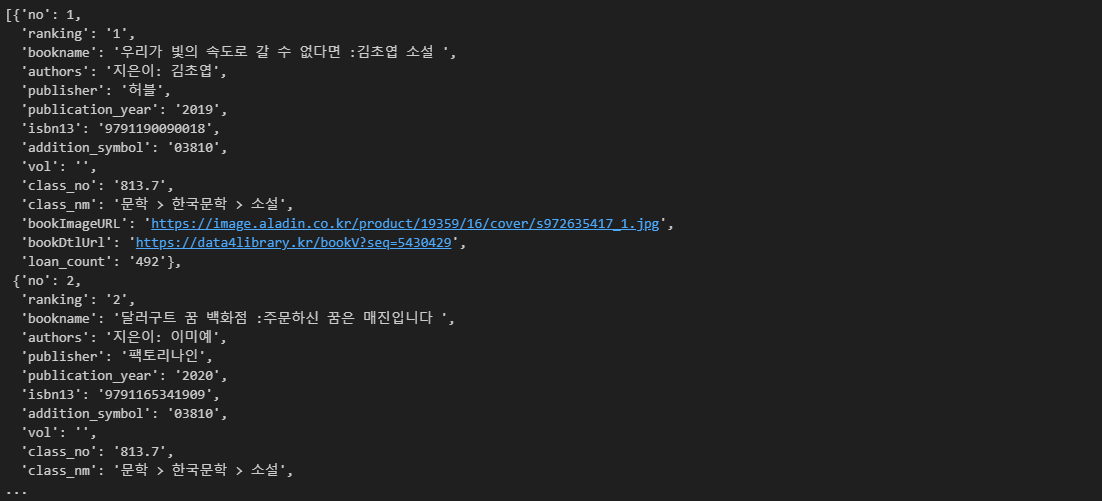
# 데이터 프레임으로 변환
books_df = pd.DataFrame(books)
books_df.head()
# 다음에 실습하기 위해 json파일로 저장
books_df.to_json('20s_best_book.json')웹 스크래핑
위에서 API로 가져온 데이터에는 책의 쪽수에 대한 정보가 존재하지 않는다
쪽수에 대한 데이터를 도서 판매 사이트 'Yes 24' 에서 웹스크래핑을 통해 가져오는 것이 목표
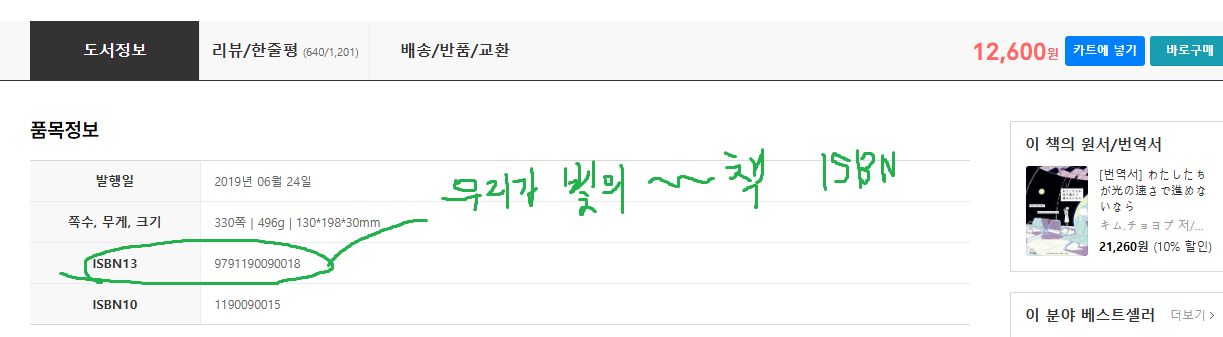
먼저 한권의 책('우리가 빛의 속도로 갈 수 없다면')에 대해서 쪽수 정보를 추출해보자
1. yes24에서 '우리가 빛의 속도로 갈 수 없다면'의 ISBN을 찾는다
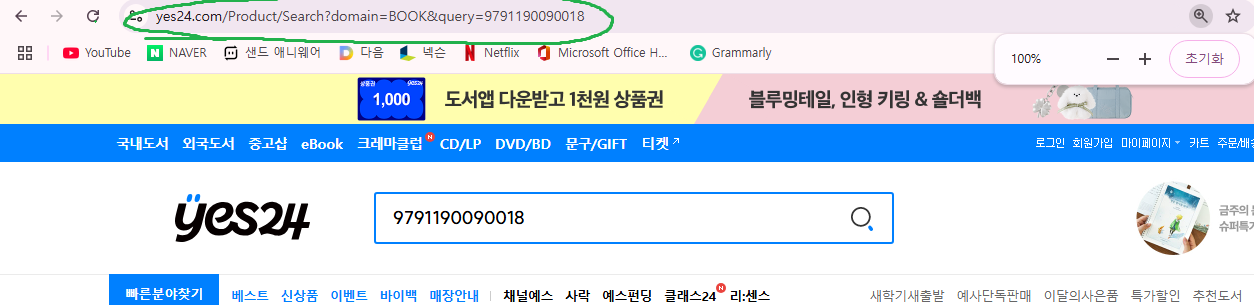
2. 도서 검색결과 페이지에 접근할 수 있는 URL 생성
3. 도서 검색결과 페이지의 HTML을 문자열로 추출
4. 페이지의 HTML 텍스트를 구조적으로 변경하는 '파싱' 수행
5. 원하는 태그 추출 (도서의 제목)
6. 원하는 태그 내부의 속성의 값을 추출
7. 도서 상세정보 페이지로 접근할 수 있는 URL 생성
8. 도서 상세정보 페이지에서 쪽수 정보 찾기
9. 쪽수 정보 추출 성공
# 2. 도서 검색결과 페이지에 접근할 수 있는 URL 생성
# '우리가 빛의 속도로 갈 수 없다면'의 ISBN
isbn = 9791190090018
# 검색창의 URL과 검색내용을 담을 수 있는 포맷을 포함한 문자열
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# 3. 도서 검색결과 페이지의 HTML을 문자열로 추출
r = requests.get(url.format(isbn))
# 4. 페이지의 HTML 텍스트를 구조적으로 변경하는 '파싱' 수행
soup = BeautifulSoup(r.text, 'html.parser')
# 5. 원하는 태그 추출 (도서의 제목)
# soup.find(태그이름, attrs={속성명: 속성값})
prd_link = soup.find('a', class_='gd_name')
# 6. 원하는 태그 내부의 속성의 값을 추출
print('도서 상세정보 페이지의 링크 뒷부분 :', prd_link['href'])
# 7. 도서 상세정보 페이지로 접근할 수 있는 URL 생성
url = 'http://www.yes24.com' + prd_link['href']
r = requests.get(url)
사진을 보면 3번(쪽수의 정보가 담긴 태그와 속성)을 보면 2번의 태그와 완전히 같다는 것을 알 수 있다
그래서 해당 태그와 속성을 find() 메서드로 가져오면 2번의 값을 가져오게된다
3번의 정보를 가져오기 위해서는 2번과 3번을 포함하는 태그인 1번을 먼저 추출하고
그 안에서 find_all 메서드로 2번과 3번을 불러온 뒤 그 중 3번을 가져오기로 했다
(교재에서는 좀 더 복잡한 방법을 쓰지만 비효율적이라고 생각해서 이 방법을 사용했다)
# 8. 도서 상세정보 페이지에서 쪽수 정보 찾기
# 상세정보 페이지 파싱
soup = BeautifulSoup(r.text, 'html.parser')
# 상세정보 페이지에서 도서정보 태그 추출
prd_detail = \
soup.find('table', attrs = {'class' : 'tb_nor tb_vertical'}) \ # 1번 태그 추출
.find_all('td', class_ = 'txt lastCol') # 1번 태그 안에서 2,3번 태그 추출
# 9. 쪽수 정보 추출 성공
prd_detail[1] # 1번 태그 중에서 2번째 원소가 쪽수에 대한 정보라서 [1] 사용
모든 인기도서의 쪽수 정보 추출하기
# 도서의 ISBN을 받아 쪽수 정보를 가져오는 함수 생성
def get_page_cnt(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# ISBN 검색결과 페이지 HTML 문자열 추출
r = requests.get(url.format(isbn))
# 파싱
soup = BeautifulSoup(r.text, 'html.parser')
# ISBN 검색결과 페이지 HTML에서 도서 제목 태그 추출
prd_info = soup.find('a', attrs={'class':'gd_name'})
if prd_info == None:
return ''
# 도서 상세정보 페이지 링크 생성
url = 'http://www.yes24.com'+prd_info['href']
# 상세정보 페이지 HTML 문자열 추출
r = requests.get(url)
# 파싱
soup = BeautifulSoup(r.text, 'html.parser')
# 상품 상세정보에서 쪽수 태그 추출
prd_detail = soup.find('table', attrs = {'class' : 'tb_nor tb_vertical'}) \
.find_all('td', class_ = 'txt lastCol')
# 쪽수,무게,크기 정보의 텍스트를 가져와서 공백으로 분할하여 첫번째 텍스트를 가져온다
return prd_detail[1].get_text().split()[0]
# 결과 확인
get_page_cnt(9791190090018)
# 인기도서 10개만 가져와서 쪽수를 가져와보자
books_top10 = books.head(10).copy()
# 데이터 프레임 확인
books_top10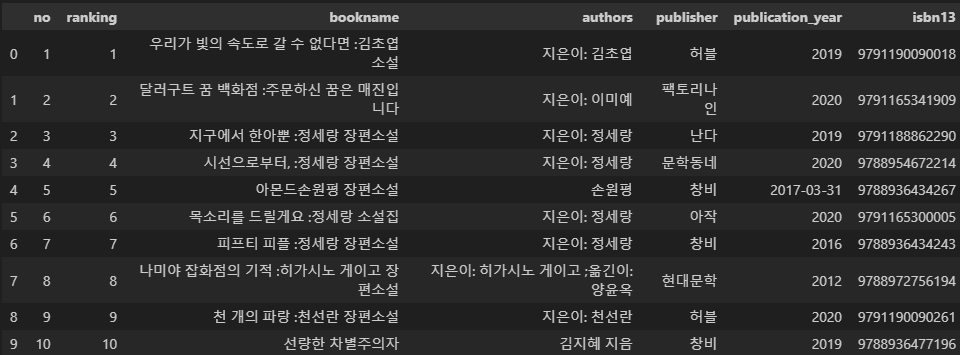
# apply 메서드로 isbn13 열에 함수 적용한 쪽수 열 생성
books_top10['쪽수'] = books_top10['isbn13'].apply(get_page_cnt)
# 확인
books_top10
# 교재에는 다른 방법으로 했지만
# 코드가 너무 길어서 더 직관적인 방법으로 작성했다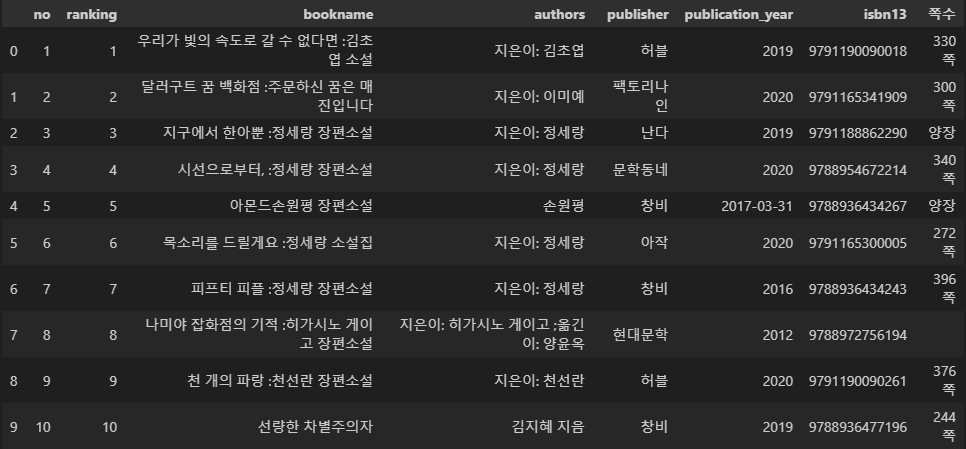
데이터 정제하기 메서드
# 정제용 데이터 다운
gdown.download('https://bit.ly/3RhoNho', 'ns_202104.csv', quiet = False)
# 데이터 로드
df = pd.read_csv('ns_202104.csv', low_memory = False)
# 데이터 확인
df.head()
# 데이터 정제 메서드 사용법
# loc 메서드로 행, 열 선택
loc_df = df.loc[:,['번호', '등록일자']] # 모든 행, 번호와 등록일자 열만 선택
loc_df2 = df.loc[:, '번호' : '등록일자'] # 모든 행, 번호부터 등록일자 열만 선택
loc_df3 = df.loc[2:5,:] # 2~5 행, 모든 열 선택
# drop 메서드로 행, 열 삭제
drop_col_df = df.drop('Unnamed: 13', axis = 1) # 열삭제
drop_row_df = df.drop([0,1], axis = 0) # 행삭제
# dropna 메서드로 결측치 행, 열 삭제
dropna_col_df = df.dropna(axis = 1) # 결측치 존재 열 삭제
dropna_row_df = df.dropna(axis = 0) # 결측치 존재 행 삭제
# [] 연산자로 행 선택
brack_row_df = df[2:5] # []에 정수를 넣으면 행 선택
brack_col_df = df[['도서명', '저자', '발행년도']] # []에 열 이름을 넣으면 열 선택
# 선택한 열 기준으로 중복된 행 수 출력
sum(df.duplicated(subset = ['도서명','저자']))
# 중복된 행 불리언 추출
df.duplicated(subset = ['도서명', '저자', 'ISBN'], keep = Fasle) # 모든 중복된 행 True
df.duplicated(subset = ['도서명', '저자', 'ISBN'], keep = 'first') # 첫번째 중복행은 False, 나머지 중복행은 True
# 중복값 제거
df['도서명'].drop_duplicates()
# 그룹화 후 연산
# '4개의 열을 기준으로 그룹화해서 대출건수의 합을 계산
groupby_df = df[['도서명', '저자', 'ISBN', '권', '대출건수']]
group_df = groupby_df.groupby(['도서명', '저자', 'ISBN', '권'], dropna = False).sum()
# 인덱스 설정
set_idx_df = df.set_index(['도서명','저자','ISBN', '권']) # 인덱스 설정
reset_idx_df = set_idx_df.reset_index() # 인덱스 초기화
# 결측치 다루기
df.isna().sum() # 결측치 수 확인_1
df.isnull().sum() # 결측치 수 확인_2
df.loc[0, '도서명'] = None # 결측치 삽입
fillna_df = df.fillna('결측치') # 결측치 채우기
# 값 바꾸기 (4가지 예시)
replace_df = df.replace('결측치', '새로운값')
replace_df2 = df.replace(['원래값_1', '원래값_2'], ['새로운값_1', '새로운값_2'])
replace_df3 = df.replace({'원래값_1' : '새로운값_1'})
replace_df4 = df.replace({'변수이름' : {'원래값_1' : '새로운값_1', '원래값_2' : '새로운값_2'}})정규 표현식 사용해서 데이터 정제하기
# 정규표현식 사용법 1
import re
# 저자 열은 '김동훈 지음, 임재희 옮김' 과 같은 형식으로 적혀있다
# 여기서 지음과 옮김이라는 글자를 없애보자
re_df = df.copy()
re_df = re_df.replace({'저자' : {r'\s?지음|옮김\s?' : ''}}, regex = True) # 문자열앞에 r을 붙여서 정규표현식을 사용
re_df.head()
# . = 아무문자열
# \s = 공백
# ? = 앞의 문자가 0개 또는 한개존재
# | = or 의미
# 정규표현식 사용법 2
# 발행년도 열에는 4자리 숫자만 존재해야한다
# 그런데 이 조건을 따르지 않는 케이스들이 있으므로
# 이 케이스들을 네자리 숫자로 만든다
# 데이터 프레임 생성
re_df = df.copy()
# 데이터 행의 수는 401,682행이다
print('1. 데이터 프레임 행 수 확인', re_df.shape[0])
# 결측치 수는 17개이다
print('2. 결측치 수 확인', re_df['발행년도'].isnull().sum())
# 먼저 문자열을 포함하는 케이스 수 출력
print('3. 문자열 포함 케이스 수', re_df['발행년도'].str.contains(r'\D', na = True).sum()) # na = True는 결측치를 True로 간주
# 문자열을 포함하는 케이스 중 문자열 삭제
re_df['발행년도'] = re_df['발행년도'].replace(r'.*(\d{4}).*', r'\1', regex = True)
# 다시 문자열을 포함하는 케이스 수 출력
print('4. 삭제 후 문자열 포함 케이스 수', re_df['발행년도'].str.contains(r'\D', na = True).sum())
# 확인
print('\n5. 문자열 포함 케이스 직접확인')
print(re_df[re_df['발행년도'].str.contains(r'\D', na = True)]['발행년도'].head(5))
print()
# 결측치거나 알 수 없는 값이기 때문에 모두 -1 으로 처리
unkown = re_df['발행년도'].str.contains(r'\D', na = True)
re_df.loc[unkown, '발행년도'] = '-1'
# 모든 값이 네자리 숫자로 이루어진 문자열로 된 것을 확인
print('6. 삭제 후 문자열 포함 케이스 수', re_df['발행년도'].str.contains(r'\D', na = True).sum())
# 발행년도 열을 object -> int32 로 변환
re_df['발행년도'] = re_df['발행년도'].astype('int32')
print('7. 숫자형 열로 변환 확인', re_df['발행년도'].dtypes)
# 비정상적인 값 -1 로 대체 (4000년 이상인 케이스)
print('8. 4000년 이후인 케이스 수 확인', re_df['발행년도'].gt(4000).sum())
print('9. 1800년 이전인 케이스 수 확인', re_df['발행년도'].lt(1800).sum())
outlier = (re_df['발행년도'].gt(4000) | re_df['발행년도'].lt(1800))
re_df[outlier] = -1
# 이상한 값 케이스 수 확인
print('10. 이상한 값인 케이스 수 확인', re_df[re_df['발행년도'] == -1].shape[0])
발행년도 열에 결측치 및 이상치인 값을 웹스크래핑으로 채우기
import requests
from bs4 import BeautifulSoup
# 발행년도가 이상치인 데이터의 인덱스
update_idx = re_df[re_df['발행년도'] == -1].index
# ISBN을 받아서 연도를 가져오는 함수를 만들어보자
def get_year(isbn):
try:
# 검색결과 페이지 URL 생성
url_1 = 'https://www.yes24.com/product/search?query={}'
# 검색결과 페이지 HTML 추출
r = requests.get(url_1.format(isbn))
# 파싱
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
url_info = soup.find('a', attrs={'class':'gd_name'})
if url_info == None:
return ''
url_2 = 'http://www.yes24.com' + url_info['href']
# 상세정보 페이지 HTML 추출
r = requests.get(url_2)
# 상세정보 페이지 파싱
soup = BeautifulSoup(r.text, 'html.parser')
info_table = soup.find('table', attrs = {'class' : 'tb_nor tb_vertical'}) \
.find_all('td', attrs = {'class' : 'txt lastCol'})
year = info_table[0].get_text().split()[0]
except:
year = ''
return year
# 함수 적용
re_df.loc[update_idx, '발행년도'] = re_df.loc[update_idx, 'ISBN'].apply(get_year)
# 4자리 숫자로 변경
re_df['발행년도'] = re_df['발행년도'].replace(r'.*(\d{4}).*', r'\1', regex = True)
re_df[re_df['발행년도'] == ''] = '-1'
re_df['발행년도'] = re_df['발행년도'].astype('int32')
# yes24에도 발행년도 정보가 없는 도서는 데이터에서 제외
re_df = re_df[re_df['발행년도'] != -1]
# 발행년도가 -1인 케이스가 있는지 확인
re_df[re_df['발행년도']== -1]
# 결과 확인
re_df.head()
기술 통계 메서드
# 기술 통계량 메서드
df['대출건수'].mean() # 평균 계산
df['대출건수'].median() # 중앙값 계산
df['대출건수'].max() # 최댓값 계산
df['대출건수'].min() # 최솟값 계산
df['대출건수'].quantile(0.65) # 65% 분위에 해당하는 값
df['대출건수'].var() # 분산 계산
df['대출건수'].std() # 표준편차 계산
df['대출건수'].mode() # 최빈값 계산
# numpy 기술 통계 함수
np.average(df['대출건수']) # 평균 계산
np.mean(df['대출건수']) # 평균 계산
np.median(df['대출건수']) # 중앙값 계산
np.min(df['대출건수']) # 최솟값 계산
np.max(df['대출건수']) # 최댓값 계산
np.quantile(df['대출건수'], 0.65) # 65% 분위 계산
np.var(df['대출건수']) # 분산 계산
np.std(df['대출건수']) # 표준편차 계산시각화
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet = False)
df = pd.read_csv('ns_book7.csv', low_memory = False)
df.head()
# 그래프 기본값 변경경
# rcParams 는 맷플롯립 그래프의 기본값을 관리하는 객체이다
# dpi(dots per inch)는 1인치당 점의 개수를 의미 (기본값은 100)
# DPI 기본값 바꾸기
plt.rcParams['figure.dpi'] = 150
# 산점도 마커를 별모양으로 바꾸기
plt.rcParams['scatter.marker'] = '*'
여러개의 그래프 그리기
# subplots으로 여러개의 그래프 그리기
fig, ax = plt.subplots(2, figsize = (8,3)) # 그림은 2개, 크기는 10x4 인치
# 첫번째 그림
ax[0].scatter(df['도서권수'], df['대출건수'], alpha = 0.1)
ax[0].set_xlabel('x') # x 축 이름 설정
ax[1].set_ylabel('y') # y 축 이름 설정
ax[0].set_title('scatter plot') # 그림1 제목 설정
# 두번째 그림
ax[1].hist(df['대출건수'], bins = 100)
ax[1].set_yscale('log')
plt.show()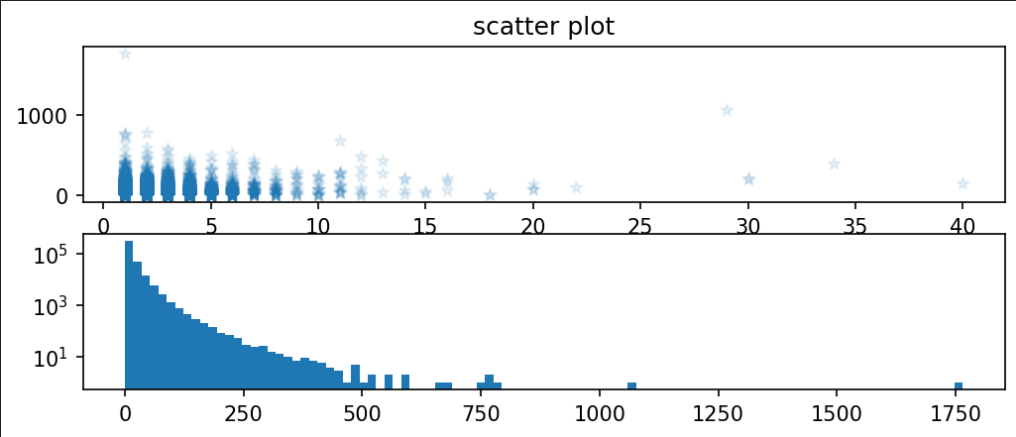
선그래프 그리기
# 선그래프용 데이터 프레임 생성
# '발행년도' 별 도서의 개수를 기록한 데이터 프레임 생성
sort_df = df['발행년도'].value_counts()
# 인덱스(발행년도)순으로 정렬
sort_df = sort_df.sort_index()
# 이상치 제거 (2030년 이전 데이터만 추출)
sort_df = sort_df[sort_df.index <= 2030].copy()
sort_df.head()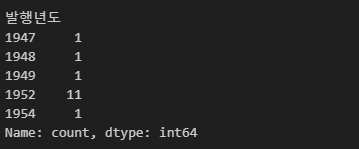
# 선그래프 그리기
# 시각화
plt.plot(sort_df, '*-g') # 그래프 모양 한번에 설정 = *-g (마커모양 *, 선모양 -, 그래프색상 green)
plt.title('title')
# 텍스트 표시
for idx, val in sort_df[::5].items(): # 5행마다 텍스트 표시
# 그래프에 텍스트 표시
plt.annotate(val, (idx,val), # .annotate(표시할 텍스트, (x좌표, y좌표))
xytext=(2,2), # 우측으로 2, 위쪽으로 2 텍스트 이동
textcoords = 'offset points') # xytext 의 이동기준을 픽셀단위로 설정
# 출력
plt.show()
# 텍스트 이동을 하기위해
# .annotate(val, (idx + 2, val + 2)) 를 사용하는 것은
# y축의 데이터 범위가 넓기 때문에 티가 나지 않는다
# 그래서 상대적으로 이동시키는 xytext와 textcoords를 사용한다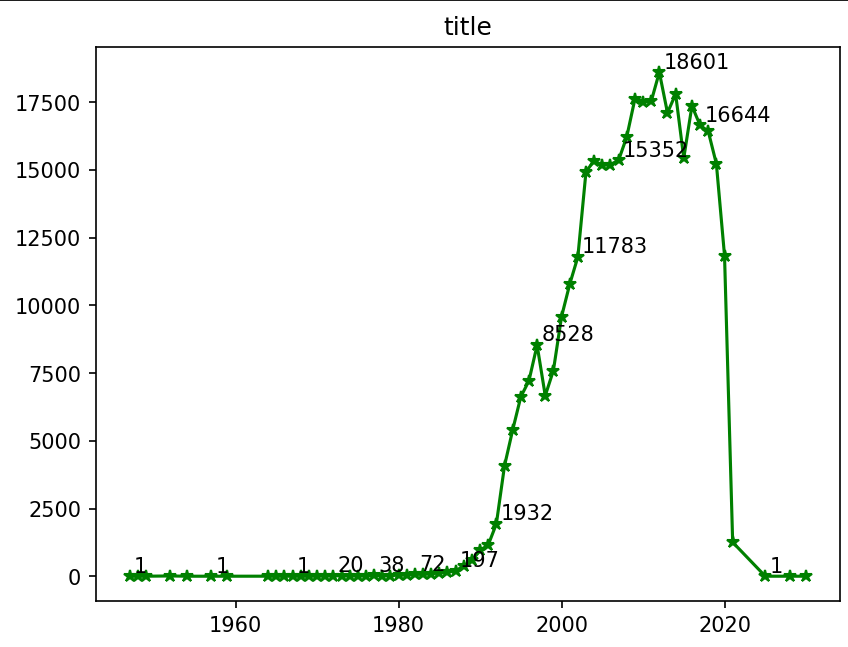
막대 그래프 그리기
# 막대그래프용 데이터 프레임 생성
category_df = df.copy()
# 주제분류번호의 앞자리를 기준으로 열 대체
category_df['주제분류번호'] = category_df['주제분류번호'].str[0]
# 결측치 -1 처리
category_df['주제분류번호'] = category_df['주제분류번호'].fillna('-1')
# 주제분류번호 별 케이스 개수 데이터 프레임 생성
category_df = category_df['주제분류번호'].value_counts()
# 데이터 확인
category_df.head()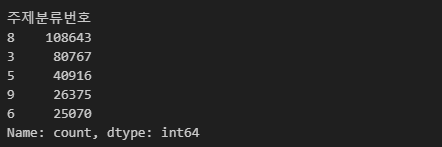
# 막대 그래프 그리기
# 시각화
plt.bar(category_df.index, category_df.values)
plt.title('title')
plt.xlabel('x')
plt.ylabel('y')
for idx, val in category_df.items():
plt.annotate(val, (idx, val),
xytext = (-15,2),
textcoords= 'offset points')
plt.show()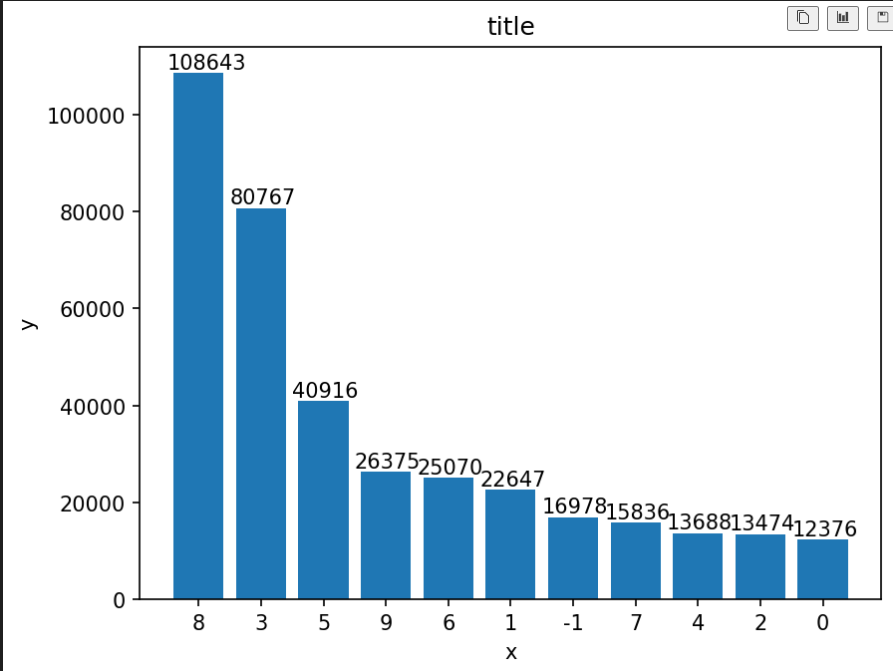
# 가로 막대그래프 그리기
# 시각화
plt.barh(category_df.index, category_df.values, height = 0.7, color = 'blue')
plt.title('title')
plt.xlabel('x')
plt.ylabel('y')
for idx, val in category_df.items():
plt.annotate(val, (val, idx),
xytext = (15,0), # 텍스트 위치 변경
textcoords= 'offset points', # 텍스트 위치 변경 기준 변경
fontsize = 8, # 글자 크기
ha = 'center', # 텍스트 중앙 정렬
color = 'red') # 글자 색상
plt.show()
여러가지 옵션을 사용해서 시각화
# 기본 옵션 설정
# 해상도 설정
plt.rcParams['figure.dpi'] = 100
# 한글 폰트 설정 (안하면 그래프에서 한글이 깨진다)
plt.rcParams['font.family'] = 'NanumGothic'
# 맷플롯립으로 폰트 설정 하기
# plt.rc('font', family='NanumBarunGothic', size=11)
# 시각화 용 데이터 프레임 생성
# 도서 수 top30 출판사 목록 추출
top30 = df['출판사'].value_counts()[:30]
# top30 출판사인 케이스만 True인 bool 객체 생성
top30_bool = df['출판사'].isin(top30.index)
# top30 출판사에 해당하는 데이터 프레임 생성
df30 = df[top30_bool]
# 시각화 실습을 위해 1000개만 랜덤 추출
df30 = df30.sample(1000, random_state = 1)
print(df30.shape)
df30.head()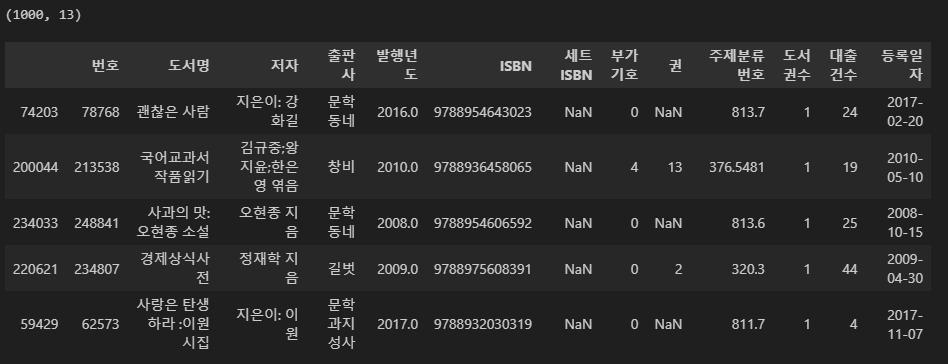
# 시각화
# 산점도 마커 모양 기본값으로 바꾸기
plt.rcParams['scatter.marker'] = 'o'
fig, ax = plt.subplots(figsize=(10, 8))
ax.scatter(df30['발행년도'], # x축 설정
df30['출판사'], # y축 설정
s = df30['대출건수'], # 대출건수 별로 마커 사이즈 조절
linewidths= 0.5, # 마커 테두리 두께
edgecolor = 'k', # 마커 테두리 색상
alpha = 0.3, # 투명도
c = df30['대출건수'] # 대출건수 별로 색상 조절
)
ax.set_title('출판사별 발행도서')
plt.show()
# 컬러맵을 사용해서 색상 지정
fig, ax = plt.subplots(figsize=(10, 8))
sc = ax.scatter(df30['발행년도'],
df30['출판사'],
linewidths=0.5,
edgecolors='k',
alpha=0.3,
s=df30['대출건수']**1.3,
c=df30['대출건수'],
cmap='jet' # 지정된 색 조합으로 색 변경
)
ax.set_title('출판사별 발행도서')
fig.colorbar(sc)
fig.show()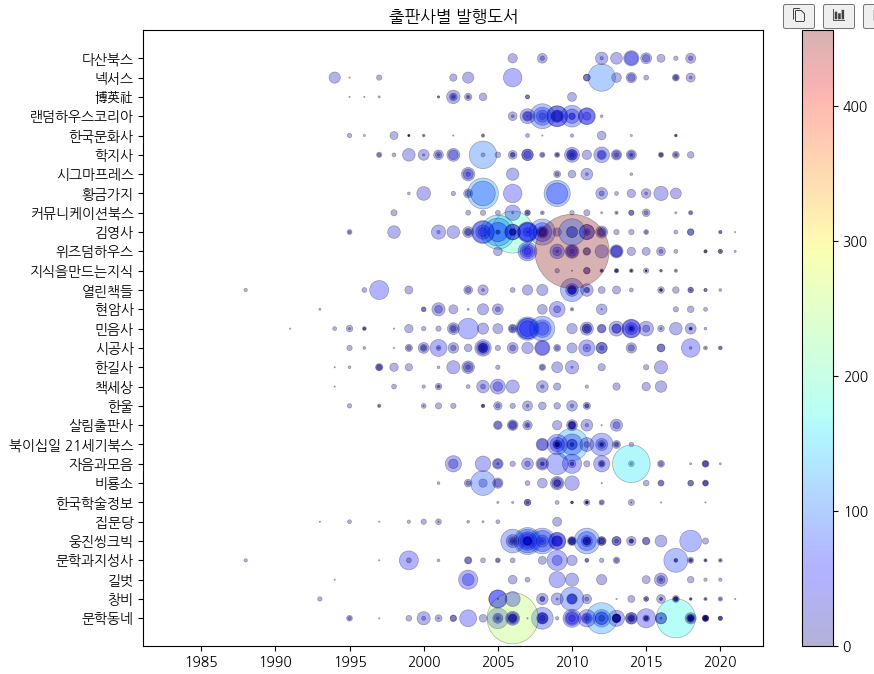
그래프 겹쳐 그리기
# 데이터 프레임 생성
df30 = df30[['출판사', '발행년도', '대출건수']].copy()
# 출판사, 발행년도 별
df30 = df30.groupby(by = ['출판사', '발행년도']).sum()
# 인덱스 리셋하기
df30 = df30.reset_index()
# 그래프 용 데이터프레임 2개 생성
df30_1 = df30[df30['출판사'] == '문학동네']
df30_2 = df30[df30['출판사'] == '민음사']
# 데이터 확인
print(df30_1.head())
print()
print(df30_2.head())
# 한 그림판에 두개의 그래프 그리기
fig, ax = plt.subplots(figsize = (8,6))
ax.plot(df30_1['발행년도'], df30_1['대출건수'], label = '문학동네') # label 범례 이름 설정
ax.plot(df30_2['발행년도'], df30_2['대출건수'], label = '민음사')
ax.set_title('제목')
ax.legend() # 위에서 설정한 이름으로 범례 설정
plt.show()
피벗
# 피벗 수행
# 출판사를 인덱스, 발행년도를 열, 대출건수를 셀값으로 한 데이터 프레임 생성
pivot_df = df30.pivot_table(index = '출판사', columns = '발행년도', values = '대출건수')
# 피벗 테이블 확인
pivot_df.head()
# --pivot_table 메서드의 values 인수에 대하여--
# 이 데이터 프레임엔 '출판사', '발행년도', '대출건수' 열 밖에 없기 때문데
# pivot 을 수행하면 pivot_table 메서드의 셀 값을 지정하는 인수인 values 설정하지 않아도
# 셀 값은 자동으로 대출건수가 된다
# 하지만 values 를 설정하지 않으면 인덱스가 복잡해지기 때문에
# values를 꼭 설정해주는 것이 좋다
# 교재에는 values 인수를 사용하지 않았기 때문에 인덱스가
# ('대출건수', 1947) 이렇게 멀티인덱스가 되어서 번거로운 작업을 거친다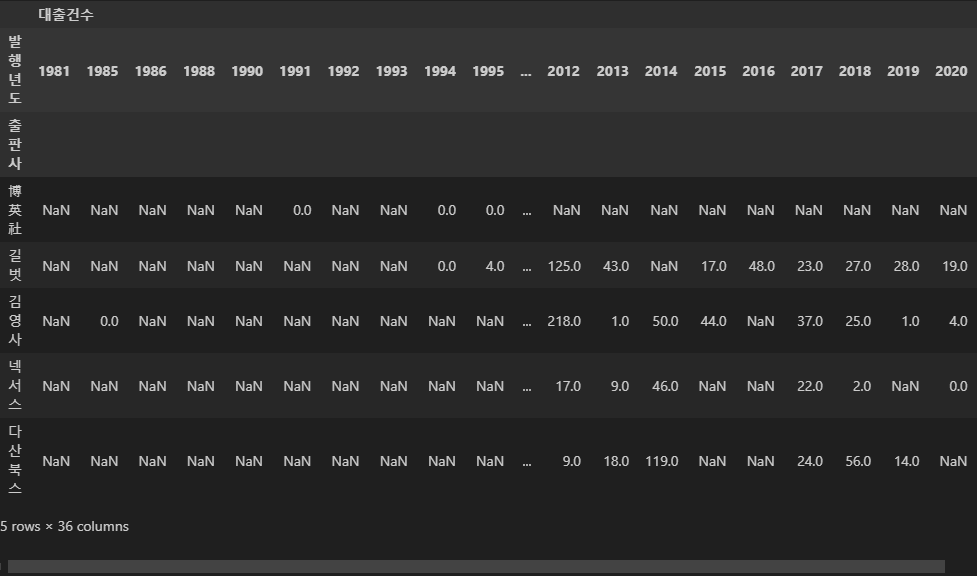
# 스택 그래프
# 스택그래프에 쌓을 5개의 출판사 이름 추출
top5_index = pivot_df.index[:5]
# x축으로 사용할 이름들 추출
cols = pivot_df.columns
# 스택 그래프
fig, ax = plt.subplots(figsize=(12, 6))
# stackplot(x축데이터, 스택 쌓을 y축 데이터, lebels = 범례에 설정할 이름들)
ax.stackplot(cols, pivot_df.loc[top5_index].fillna(0), labels=top5_index)
ax.set_title('년도별 대출건수')
ax.legend(loc='upper left') # 좌측 상단에 범례 설정
ax.set_xlim(1990, 2025) # x축 범위 설정
plt.show()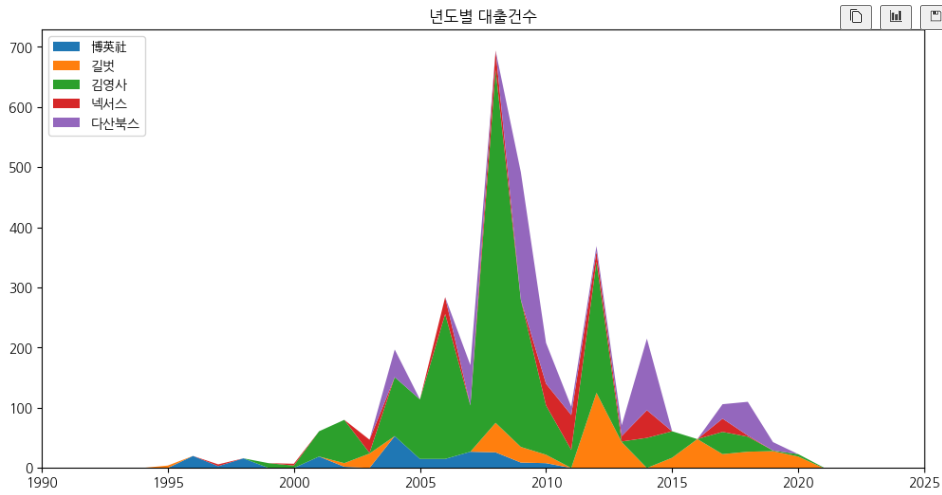
누적 막대 그래프 그리기
# 5개출판사 이름 추출
top5_index = pivot_df.index[:5]
# 5개 출판사, 2003~2020년의 대출건수 데이터 프레임 생성
stack_df = pivot_df.loc[top5_index, 2003:2020].copy()
stack_df = stack_df.fillna(0)
stack_df.head()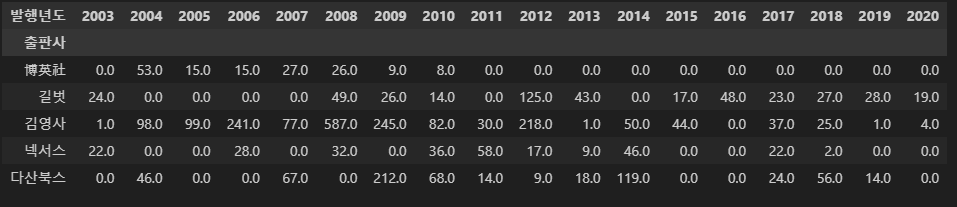
# 열의 값들이 누적합된 데이터 프레임
stack_df = stack_df.cumsum()
stack_df.head()
# 누적 막대 그래프 그리기
# 누적 막대 그래프를 그릴때, 말그대로 쌓는 것이 아니라
# cumsum()을 한 데이터 프레임에서
# 가장큰값부터 가장작은값을 가진 행까지 반복하여 겹쳐 그리면서
# 누적막대그래프처럼 생긴 그래프를 만드는 것이다
fig, ax = plt.subplots(figsize = (10,4))
# reversed를 이용해서 가장 마지막 행부터 그림 그리기
for i in reversed(range(stack_df.shape[0])):
ax.bar(stack_df.columns, stack_df.iloc[i,:], label = stack_df.index[i])
ax.set_title('연도 별 대출건수')
ax.legend(loc = 'upper left')
ax.set_xlim(2002,2021)
plt.show()
파이차트 그리기
# 파이차트 그리기
# 도서권수 top5 출판사 데이터 프레임
pie_df = df.copy()
pie_df = pie_df[['출판사', '도서명']]
pie_df = pie_df['출판사'].value_counts().reset_index()[:5]
pie_df.head()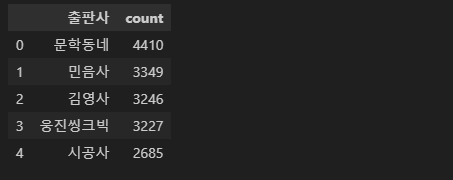
pie_cols = list(pie_df['출판사'].unique())
# 시각화
fig, ax = plt.subplots(figsize=(8, 6))
ax.pie(pie_df['count'], # 파이 차트 비율 값
labels=pie_cols, # 범주 이름
startangle= 90, # 시작 각도
autopct= '%.1f%%', # 소수점 1자리까지 표시
explode = [0.1] + [0]*4 # 첫번째 조각을 강조하고 나머지는 그대로 유지
)
ax.set_title('출판사 도서비율')
plt.show()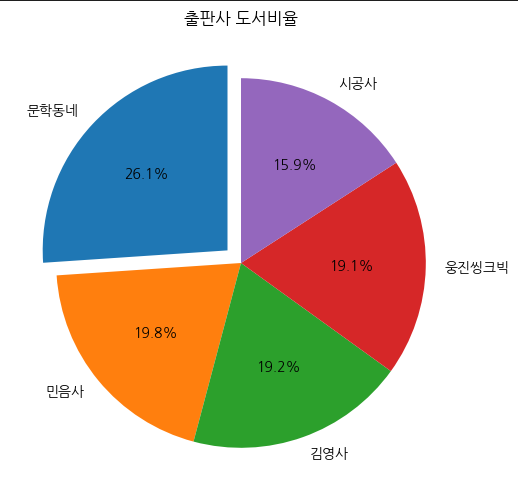
'DA 서적 정리' 카테고리의 다른 글
| 웹 크롤링 & 데이터 분석 with 파이썬 요약 1 (1) | 2025.03.12 |
|---|---|
| 혼자 공부하는 데이터 분석 with 파이썬 요약 2 (0) | 2025.03.08 |
| Do it! - 데이터 분석을 위한 판다스 입문 요약 2 (0) | 2025.02.27 |
| Do it! - 데이터 분석을 위한 판다스 입문 요약 1 (0) | 2025.02.26 |