Do it! - 데이터 분석을 위한 판다스 입문 요약 2
2025. 2. 27. 16:52ㆍDA 서적 정리
피벗과 피벗 되돌리기
'열 이름이 값일 때 넓은 데이터를 긴데이터로 만들기 (피벗 되돌리기)'
# 데이터 준비
ebola = ebola.melt(id_vars = ['Date', 'Day'])
ebola.head()# 데이터 확인
pew.head()
pew_long = pew.melt(
id_vars= 'religion', # 유지할 열 (리스트로 여러 열을 유지할 수도 있다)
var_name='income', # 되돌리기한 열 이름
value_name='count' # '열로 정리된 셀'의 열 이름
)
pew_long.head()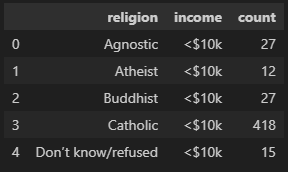
'셀 값을 열로 변형 (피벗)'
# 데이터 준비
weather.head()
weather_pivot = weather.pivot_table(
index = ['id', 'year', 'month', 'day'], # 유지할 열
columns = 'element', # 피벗할 열이름
values = 'temp' # 셀값으로 설정할 열 이름
)
weather_pivot.head(10)
문자열 셀을 나누어 두개의 열로 분할
'문자열 데이터를 나누어 두개의 열로 만들기'
# 데이터 준비
ebola = ebola.melt(id_vars = ['Date', 'Day'])
ebola.head()
# variable 열의 값들을 _ 기준으로 두 문자열로 나누어 리스트로 저장
split_col = ebola['variable'].str.split('_')
split_col.head() # 리스트로 이루어진 시리즈 객체
# 각 리스트의 첫번째 값 추출
first = split_col.str.get(0)
# 각 리스트의 두번째 값 추출
second = split_col.str.get(1)
ebola['status'] = first
ebola['country'] = second
ebola.head()
apply로 함수 적용 및 람다함수 사용법
# apply 사용법
# 간단 함수 생성
def sample_def(x):
return x**2
# 시리즈 생성
sample_list = pd.Series([1,2,3,4])
# 시리즈에 apply로 함수 적용
sample_list.apply(sample_def)
# 람다함수를 적용할 데이터 프레임 준비
df.head()
df['lambda_x'] = df['B'].apply(lambda x: x**2)
df.head()
데이터 연결하기
# 4x4 크기의 데이터 프레임 3개 준비
df1 = pd.read_csv('data/concat_1.csv')
df2 = pd.read_csv('data/concat_2.csv')
df3 = pd.read_csv('data/concat_3.csv')
# 행 방향 연결
# (행 방향 연결을 하면 중복 인덱스가 생기기 때문에 ignore_index = True를 설정해주어야한다)
concat_df = pd.concat([df1,df2,df3], axis = 0, ignore_index = True)
# 열 방향 연결
concat_df = pd.concat([df1,df2,df3], axis = 1)
# 출력
print(concat_df1, '\n')
print(concat_df2)
# 만약 결합할 행과 열의 이름이 다르다면
# 정보가 없는 셀은 Nan 으로 채워진다
# 각 데이터 프레임의 열 이름을 서로 다르게 변경
df1.columns = ['a','b','c','d']
df2.columns = ['e','f','g','h']
df3.columns = ['a','c','f','h']
# 결합
concat_df = pd.concat([df1,df2,df3]) # join = 'inner' 옵션을 설정하면 공통인 열만 결합된다
concat_df.head(10)
# 병합 (조인)
# 병합할 두개의 데이터 프레임
print(site.head(), '\n')
print(visited.head())
# 데이터 프레임 site, visited를 병합
merge_df = site.merge(visited, left_on = 'name', right_on = 'site', how = 'inner')
merge_df.head()
# how 인수는 병합 타입을 설정한다 inner,left,right,outer 가 있으며 기본값은 inner 이다
# 만약 left_on 이나 right_on 에 설정하는 병합 기준열에 중복값이 있으면
# 즉, name열의 DR-1이 3개, site열에 DR-1이 2개 있으면
# DR-1 조합이 3x2 = 6개가 되어 6개의 케이스로 증가되어 병합된다
# 일반적으로는 중복값이 있는 열을 병합 기준열로 지정하지 않는 듯 하다
agg()로 데이터 집계
import numpy as np
# 데이터 준비
df.head()
# agg()로 한번에 여러 열 집계하기
df.groupby('continent')['lifeExp'].agg([np.mean, np.median, np.std])
# 하나의 통계량만 계산하려면다음의 코드가 적당하다
# df.groupby('continent')['lifeExp'].mean()
# 열 별로 다른 집계 함수 적용
df_dict = df.groupby('year').agg(
{
'lifeExp' : 'mean', # year별 lifeExp 평균 계산
'pop' : 'median', # year별 pop 중앙값 계산
'gdpPercap' : 'median' # year별 gdpPercap 중앙값 계산
}
)
df_dict.head()
데이터 걸러내기 (필터링)
# 데이터 준비
tips.head()
# size 별 케이스 수가 30개 이상인 size만 출력
filter_df = tips.groupby('size').filter(lambda x : x['size'].count() >= 30)
filter_df.head()
# 이 코드는 그룹별로 정렬된 데이터 프레임을 반환하지 않는다
# 그룹별로 계산해봤을때의 조건을 만족한 케이스들만 불러온다
# 꼭 람다함수를 써야하는가?
# 람다함수를 쓰기 싫어서 다음과 같은 코드를 작성했는데 오류가 발생한다
# filter_df = tips.groupby('size').filter(tips.groupby('size').count() >= 30)
# 왜냐하면 filter() 는 True/False 를 반환해야하는데
# tips.groupby('size').count() >= 30 라는 조건은 데이터 프레임을 반환하기 때문이다
# 그냥 람다함수에 익숙해지자
그룹화 된 객체 다루기
# 3가지 열로 그룹화된 객체가 존재한다고 가정하자
groupby_tips = tips.groupby(['sex', 'time', 'smoker'], observed=True)['day'].count()
print(type(groupby_tips), '\n')
print(groupby_tips)
# 이 객체의 인덱스를 살펴보면 그룹기준 열들의 조합인 멀티인덱스이다
groupby_tips.index
# 그룹화 기준 열들 중 몇개만 선택해서 집계
# 인덱스열은 (sex, time, smoker) 인데 그 중 sex 열의 평균
print(groupby_tips.groupby(level = [0], observed = True).mean())
# 줄바꿈
print('\n')
# 인덱스열은 (sex, time, smoker) 인데 그 중 (sex, time) 열들의 평균
print(groupby_tips.groupby(level = [0,1], observed = True).mean())
결측치 처리
# 데이터에 빈 셀(결측치)를 Nan로 처리하지않고 그냥 두는 방법
pd.read_csv('visited.csv', keep_default_na = False)
print(visited)
# 결측치로 처리할 문자열을 지정
visited = pd.read_csv('data/survey_visited.csv',na_values = [''], keep_default_na = False)
# keep_default_na = False 로 자동으로 결측치를 처리하지 않고
# na_values = [''] 로 빈문자열을 결측치 처리
# 괄호안에 다른 문자열을 넣으면 그 문자열은 결측치 처리된다
# 열 별 결측치 구하기
visited.isnull().sum(axis = 0)
# 행 별 결측치 구하기
visited.isnull().sum(axis = 1)

# 결측치 처리방법들
# 결측치 특정 값으로 대체하기
visited.fillna('우히히 결측치 대체')
# 결측치 정방향 채우기 (결측치를 이전 케이스의 값으로 채우기)
visited.fillna(method = 'ffill')
# 결측치 역방향 채우기 (결측치를 다음 케이스의 값으로 채우기
visited.fillna(method = 'bfill')
# 결측치 보간법 채우기 (이전 케이스와 다음 케이스의 중간값으로 채우기)
visited.interpolate() # 숫자형 데이터일때만 가능하다
# 결측치 삭제
visited.dropna()# 결측치 수동 삽입
# 데이터 준비
visited_na = visited.copy()
# 2가지의 결측치로 변환 방법
visited_na.iloc[0,1] = np.nan
visited_na.iloc[1,1] = pd.NA
visited_na.iloc[2,1] = 'NaN' # (이건 그냥 'NaN'이라는 텍스트일 뿐 결측치가 아니다)
# 결측치로 변환 확인
print(visited_na, '\n')
# 결측치 처리된 셀의 타입
print(type(visited_na.iloc[0,1]))
print(type(visited_na.iloc[1,1]))
print(type(visited_na.iloc[2,1]))
자료형 변환 팁
# 자료형 변환
df['col'] = tips['col'].astype('str')
df['col'] = tips['col'].astype('float')
# 숫자열에 문자가 존재하면 해당 열은 'object' 타입으로 바뀐다
# 해당 열의 문자를 모두 결측치 처리하고 'float' 타입으로 바꾸려면
# 다음처럼 to_numeric함수와 errors 인수를 설정해주어야 한다
df['col'] = pd.to_numeric(df['col'], errors = 'coerce')문자열 처리하기
# 알아두면 좋은 문자열 메서드
# 다 외우기보단 이런 기능들이 있구나하고 대충 기억하는게 좋을듯하다
df['col1'] = df['col1'].str.capitalize() # 첫 글자를 대문자로 변환
df['col1_count'] = df['col1'].str.count('a') # 'a' 문자가 등장하는 횟수 계산
df['col1_startswith'] = df['col1'].str.startswith('A') # 'A'로 시작하는지 여부 (True/False)
df['col1_endswith'] = df['col1'].str.endswith('z') # 'z'로 끝나는지 여부 (True/False)
df['col1_find'] = df['col1'].str.find('b') # 'b'의 첫 번째 위치 찾기 (없으면 -1 반환)
df['col1_index'] = df['col1'].str.index('b') # 'b'의 첫 번째 위치 찾기 (없으면 오류 발생)
df['col1_isalpha'] = df['col1'].str.isalpha() # 알파벳 문자로만 이루어졌는지 확인
df['col1_isdecimal'] = df['col1'].str.isdecimal() # 10진수 숫자로만 이루어졌는지 확인
df['col1_isalnum'] = df['col1'].str.isalnum() # 영문자와 숫자로만 이루어졌는지 확인
df['col1_lower'] = df['col1'].str.lower() # 모든 문자를 소문자로 변환
df['col1_upper'] = df['col1'].str.upper() # 모든 문자를 대문자로 변환
df['col1_replace'] = df['col1'].str.replace('old', 'new') # 'old'를 'new'로 대체
df['col1_strip'] = df['col1'].str.strip() # 앞뒤 공백 제거
df['col1_partition'] = df['col1'].str.partition('-') # '-'을 기준으로 문자열을 나누어 튜플 반환
df['col1_center'] = df['col1'].str.center(10, '*') # 문자열을 10자 폭으로 중앙 정렬, 빈 공간 '*'로 채움
df['col1_zfill'] = df['col1'].str.zfill(5) # 문자열 길이를 5자로 맞추고 빈 공간을 0으로 채움
' '.join([str1, str2, str3]) # 문자열들 사이에 특정 문자열을 넣어 결합
str_2 = str_1.splitlines() # 문자열을 각 줄로 나누어 저장# 문자열 포맷팅
num = 50.1235
str_1 = f'문자열 중간에 {num} 이렇게 뭘 넣을수가 ㅇ있어용'
str_2 = f'숫자 표기 길이를 설정하려면 {num:.5} 이렇게'
str_3 = f'퍼센트로 표시하려면 {num:.4%} 이렇게'
str_4 = f'숫자 반올림하려면 {num:.2f} 이렇게'
print(str_1, '\n', str_2, '\n', str_3, '\n', str_4)
정규식표현
# 필요한 라이브러리
import re
# 기본 정규 표현식 기호
. # 아무 문자와 일치 (예: "a.b" -> "acb", "a2b")
^ # 문자열의 시작 부분부터 일치하는 패턴 (예: "^hello" -> "hello world")
$ # 문자열의 끝 부분과 일치 (예: "world$" -> "hello world")
* # 앞 문자가 0개 이상 반복 (예: "ab*" -> "a", "ab", "abb", "abbb" )
+ # 앞 문자가 1개 이상 반복 (예: "ab+" -> "ab", "abb", "abbb")
? # 앞 문자가 0개 또는 1개 존재 (예: "ab?" -> "a", "ab")
{m} # 앞 문자가 정확히 m번 반복 (예: "a{3}" -> "aaa")
{m,n} # 앞 문자가 최소 m번, 최대 n번 반복 (예: "a{2,4}" -> "aa", "aaa", "aaaa")
\ # 특수 문자를 그대로 사용할 수 있게 해줌 (예: "\." -> '.')
[] # 문자 집합 (예: "[abc]" -> "a", "b", "c" 중 하나)
| # OR 연산자 (예: "a|b" -> "a" 또는 "b")
() # 그룹을 만들어 묶음 (예: "(abc)+" -> "abc", "abcabc")
# 정규식
\d # 숫자 (0~9)와 일치 (예: "\d+" → "123", "45")
\D # 숫자가 아닌 문자와 일치 (예: "\D+" → "abc", "hello")
\s # 공백 문자 (스페이스, 탭, 개행)와 일치 (예: "\s+" → " ", "\t")
\S # 공백 문자가 아닌 문자와 일치 (예: "\S+" → "hello", "world")
\w # 알파벳 대소문자 or 숫자 or 밑줄(_) (예: "\w+" → "hello123")
\W # 알파벳, 숫자, 밑줄이 아닌 문자와 일치 (예: "\W+" → "@#$%", "! ")
# 같이 사용되는 메서드
re.search(pattern, string) # 문자열 전체에서 첫 번째 일치하는 부분 찾기
re.match(pattern, string) # 문자열의 시작 부분이 패턴과 일치하는지 확인 (처음부터만 매칭)
re.fullmatch(pattern, string) # 문자열 전체가 패턴과 일치하는지 확인
re.split(pattern, string) # 패턴을 기준으로 문자열을 나누어 리스트로 반환
re.findall(pattern, string) # 문자열에서 모든 패턴을 찾아 리스트로 반환
re.finditer(pattern, string) # 문자열에서 모든 패턴을 찾아 반복자로 반환
re.sub(pattern, replacement, string) # 문자열에서 패턴을 찾아 다른 문자열로 치환정규 표현식 사용 예시
# 정규 표현식으로 문자 찾기 예시
import re
text = "My phone number is 123-456-7890 and my office number is 987-654-3210."
# 모든 패턴 찾기
pattern = r"\d{3}-\d{3}-\d{4}"
phone_numbers = re.findall(pattern, text)
print(phone_numbers)
# 번호를 다른 문자로 대체
masked_text = re.sub(pattern, "***-***-****", text)
print(masked_text)
시계열 데이터 다루기 (추가)
# 필요한 라이브러리
from datetime import datetime
# 현재 시간 출력
print(datetime.now())
# 특정 시간 정보
print(datetime(1970, 1, 1))
# 특정 시간 범위 설정
time_range = pd.date_range(start = '2014-12-31', end = '2015-01-05')
# 시간범위를 인덱스로 설정하면 모든 날짜가 행 인덱스로 추가되고
# 데이터가 없는 날짜는 모든 열이 NaN값으로 표시된다
df = df.reindex(time_range)# 시간 주기 변경하기
# 다운 샘플링 : 작은 주기에서 큰 주기로 변경 (일 -> 월 주기)
# 업 샘플링 : 큰 주기에서 작은 주기로 변경 (월 -> 일 주기)
# 데이터 준비
ebola = pd.read_csv('data/country_timeseries.csv')
# Date 열을 datetime 타입으로 변경
ebola['Date'] = pd.to_datetime(ebola['Date'])
# datetime 타입 열을 인덱스로 설정
ebola = ebola.set_index('Date')
ebola.head()
# 다운샘플링하기 (일단위를 월단위로 주기 변경 (월평균))
down = ebola.resample('ME').mean()
down.head()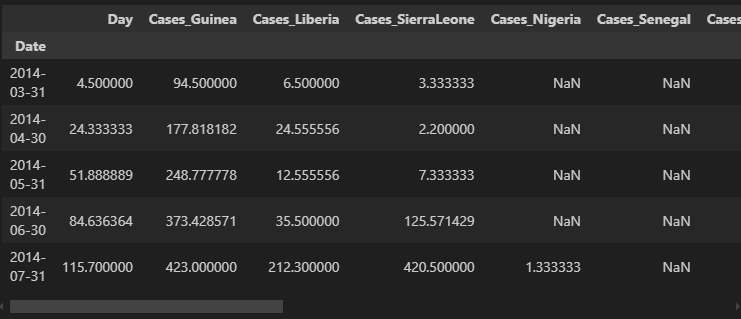
'DA 서적 정리' 카테고리의 다른 글
| 웹 크롤링 & 데이터 분석 with 파이썬 요약 1 (1) | 2025.03.12 |
|---|---|
| 혼자 공부하는 데이터 분석 with 파이썬 요약 2 (0) | 2025.03.08 |
| 혼자 공부하는 데이터 분석 with 파이썬 요약 1 (0) | 2025.03.08 |
| Do it! - 데이터 분석을 위한 판다스 입문 요약 1 (0) | 2025.02.26 |